Muy buenas a todos,
Mi nombre es Sergi de la Torre y vamos a dedicar el post de hoy a un producto que parece que este año va a dar mucho que hablar, en concreto nos referimos a VMware Horizon Mirage.
Muchos de vosotros lo conoceréis, y tal vez muchos será la primera vez que escucháis al respecto de este producto. Horizon Mirage no es un nuevo software recién sacado del horno por VMware sino que se trata del software de la compañía Wanova que el año pasado VMware adquirió y que actualmente ha integrado dentro de su portfolio dirigido a las soluciones de EUC (End User Computing) y que como bien he comentado dará mucho que hablar.
¿Qué es VMware Horizon Mirage?
Horizon Mirage se trata una de las soluciones que proporciona VMware para reducir de manera dramática el OpEx (Operational Expenses) consiguiendo reducir los recursos necesarios para mantener nuestra infraestructura de microinformática.
¿Cómo explicar de manera rápida, y sencilla que és Mirage? Bien, la manera más resumida para dar una idea clara de que es Mirage cuando alguien me pregunta es: “¿Conoces la virtualización de escritorios? ¿Conoces las ventajas que proporciona a nivel de gestión centralizada de los desktops? ¿Los ahorros en OpEx que te facilita? Bien, pues Horizon Mirage te ofrece la misma facilidad y ahorros en OpEx pero sin ningún tipo de virtualización, es decir, la ejecución del Sistema Operativo y las aplicaciones sigue siendo en local, en el dispositivo final del usuario”
¿Cómo funciona Horizon Mirage?
Para poder explicar el funcionamiento de la solución, explicaremos como segmenta las distintas partes de un desktop/laptop y como se gestionan en nuestro servidor.
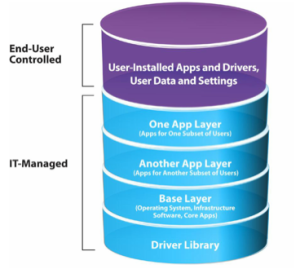
Mirage trabaja con un conjunto de capas claramente diferenciadas y nos permite poder intercambiar estas capas desde nuestro servidor central sin ningún tipo de intervención del usuario (miento aquí, el usuario deberá reiniciar su equipo para aplicar los cambios de capa. Complicado, eh!?). Podemos ver a continuación las distintas capas que gestiona el sistema:
Podemos ver 2 categorías claras: las capas gestionadas por el usuario y las capas gestionadas por el personal de TI.
Las capas gestionadas por el usuario son sus propios datos, su configuración (fondo de pantalla, favoritos, etc) así como las aplicaciones que él mismo se instale sobre su equipo
En cambio, las capas gestionadas por TI son:
- Driver Library: Uno de los puntos a gestionar en este entorno son los drivers. Mirage gestiona una librería de drivers que el administrador deberá ir alimentando con los drivers de todos los dispositivos que hayan en el parque de PCs. Esto permite migrar por completo un equipo con todos sus datos hacia otro equipo con Hardware completamente distinto sin ningún tipo de problema.
- Base Layer: Esta capa incluye el sistema operativo así como las aplicaciones corporativas que queramos desplegar a todo el conjunto de usuarios. Un ejemplo de aplicaciones comunes a todos los usuarios podría ser el antivirus, Microsoft Office, etc.
- App Layer: Estas capas serán desplegadas para instalar de manera centralizada aplicaciones a distintos usuarios. Podremos crear grupos de aplicaciones para crear paquetes de aplicaciones departamentales y además nos permitirá lanzar actualizaciones de las aplicaciones de manera centralizada sin ningún tipo de actuación sobre los equipos cliente.
Arquitectura de la solución
¿Que mejor explicación para la arquitectura que una imagen?
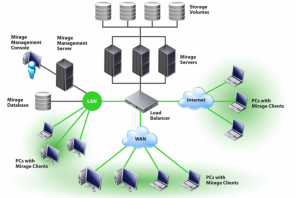
Como podéis ver, el despligue de Horizon Mirage consta de distintos elementos. Pasamos a detallar estos elementos a continuación:
– Storage Volumes. Se trata de los volumenes donde se almacenarán los distintos datos tales como las imagenes base, las capas de aplicación, la librería de drivers, los datos de usuario,e tc. Estos Storage Volumes será recomendable presentarlos como un recurso compartido a través de CIFS para poder ser usados por varios Mirage Server, ya que esto nos permitirá poder redundar y balancear la carga entre distintos servidores, aunque en cualquier caso están soportados los almacenamientos tipo SAN, NAS y almacenamiento local.
- Muy importante. Horizon Mirage realiza deduplicación a nivel de fichero y acto seguido a nivel de bloque. Esto permite reducir el tamaño que ocupan los distintos CVDs en disco de manera drástica
- Nota a tener en consideración. VMware recomienda usar como “rule of thumb” (regla estándard) 15GB por usuario a la hora de dimensionar el tamaño del almacenamiento.
– Mirage Servers. Se trata de el/los servidores/es encargados de la transferencia de los ficheros y de la comunicación con los dispositivos finales. Deberemos desplegar varios de servidores con este rol cuado nos interese proporcionar toleráncia a fallos o bien si necesitamos escalar para poder dar servicio a un número mayor de dispositivos finales. Recordemos que cada Mirage Server soporta 1.500 dispositivos gestionados (si se trata de un servidor físico) o 300 dispositivos gestionados (servidor virtual). El número máximo de serivodres en el clúster es de 10 nodos.
– Mirage Management Server. Este servidor es el encargado de la gestión y administración de nuestro clúster de Servidores de Mirage. Un único nodo gestionará los distintos Mirage Servers que tengamos. Necesita de un servidor de base de datos, en concreto una BBDD de Microsoft SQL Server
– Mirage Management Console. No se trata de un servidor en si, pero será el punto desde el que gestionaremos el entorno. Se trata del entorno gráfico que nos proporcionan para el Mirage Management Server. Esta consola se instala como un Snap-In de MMC.
A nivel de conectividad desde los clientes hacia el/los servidor/es de Mirage podemos ver que podemos conectar desde la mayoría de tipos de conexión: LAN, WAN e Internet. Es importante mencionar que Mirage dispone además de la deduplicación que hemos comentado anteriormente en almacenamiento, deduplicación a la hora de enviar los bloques, con lo cual, antes de enviar ningún bloque a través de la red realiza las siguientes optimizaciones:
- Deduplicación a nivel de fichero
- Deduplicación a nivel de bloque
- Compresión de los paquetes a enviar
Con esto el sistema consigue reducir enormemente el tráfico necesario a enviar. Así mismo, no se enviará ningún archivo que ya resida en el servidor a la hora de realizar la cópia. En caso que ese archivo ya se encuentre en el servidor, en su lugar se almacenará un apuntador hacia el archivo existente, con lo cual también tendremos una reducción del espacio en disco.
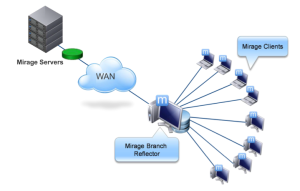
En cuanto a las oficinas remotas, también existe una funcionalidad muy interesante llamada Branch Reflector. Esta funcionalidad permite seleccionar un equipo cliente como servidor dentro de la sede. Este equipo seguirá siendo usado por un usuario, pero a la vez será el repositorio de las imagenes y dónde accederán a descargar las nuevas capas los distintos equipos que se encuentren en esa sede. Esto consigue que las imágenes solo sean descargadas una única vez desde la sede hacia el Branch Reflector y este las distribuya entre los distintos equipos de manera local.
Todo esto es muy bonito y interesante pero, ¿Para que puedo usar Mirage?
Mirage es un producto que podemos usar para el dia a dia en la administración de los dispositivos finales, pero los casos de uso más claros tratamos de exponerlos a continuación:
a) Migración de Windows XP a Windows 7
Como hemos comentado, Mirage nos segmenta cada una de las maquinas en distintas capas que podemos intercambiar sin ningún problema. Una de estas capas es la de sistema operativo, con lo cual nos permite migrar de manera muy fácil nuestro parque de Windows XP hacia Windows 7.
b) Disaster Recovery
Un usuario pierde su portátil en el aeropuerto, o bien el disco duro muere, o se le ha caído el café encima… Todos sabemos que pueden pasar mil cosas! Bien, como hemos comentado todos los datos del equipo del cliente están guardados en nuestro servidor Mirage, desde el S.O., las aplicaciones, sus datos, sus configuraciones… Mirage dispone de un asistente para que en caso que ocurra cualquiera de estas desgracias poder mover estos datos hacia otro equipo y el equipo esté exactamente igual que el anterior, con sus datos, configuración, apps, etc.
c) Cambio de equipos PC
Como os podéis imaginar este caso es exactamente igual que el anterior, así que no hay ningún problema en hacerlo.
d) Entrega/actualización de aplicaciones de manera centralizada
Al poder entregar distintas capas de manera centralizada, podemos hacer llegar nuevas aplicaciones o bien actualizaciones de aplicaciones que tiene el usuario sin que el administrador se tenga que levantar de su mesa. Bueno… dejémosle que se levante a tomar un café al menos y lance el despliegue 😉
¿Es Horizon Mirage competencia de Horizon View?
La respuesta es: ¡Rotundamente No!
La apuesta de VMware por este producto es para poder ofrecer una solución completa para la gestión del parque de microinformática para todas las distintas necesidades y distintos perfiles que podemos encontrar dentro de una empresa.
Uno de los mensajes que suelo lanzar cuando tengo una conversación respecto a virtualización de escritorios es: “Si alguien te dice que puedes virtualizar el 100% de tus escritorios, huye, esa persona te está mintiendo”. De la misma manera usaría el mismo mensaje en cuanto a Horizon Mirage. Debemos tener en cuenta que según las necesidades de cada usuario será necesario ir hacia una solución u otra, o incluso la combinación de ambas soluciones.
En este sentido creo que el movimiento de VMware en su aproximación hacia una solución global para los dispositivos de usuario final es muy acertada, y con ello han sacado la llamada Horizon Suite.
Horizon Suite no es más que un paquete que incluye los distintos productos tales como: View, Mirage y Horizon Workspace, consiguiende ofrecer una solución global a los problemas actuales de la informática de usuario. Obviamente es posible que no necesitemos todos los productos o realicemos una aproximación por fases, en ese caso todos los productos se pueden seguir adquiriendo por separado.
Bien, esto es todo por hoy respecto a Mirage. Espero veros pronto con los siguientes posts de Mirage enfocados a su instalación, administración y casos de uso.
Saludos!!
Sergi